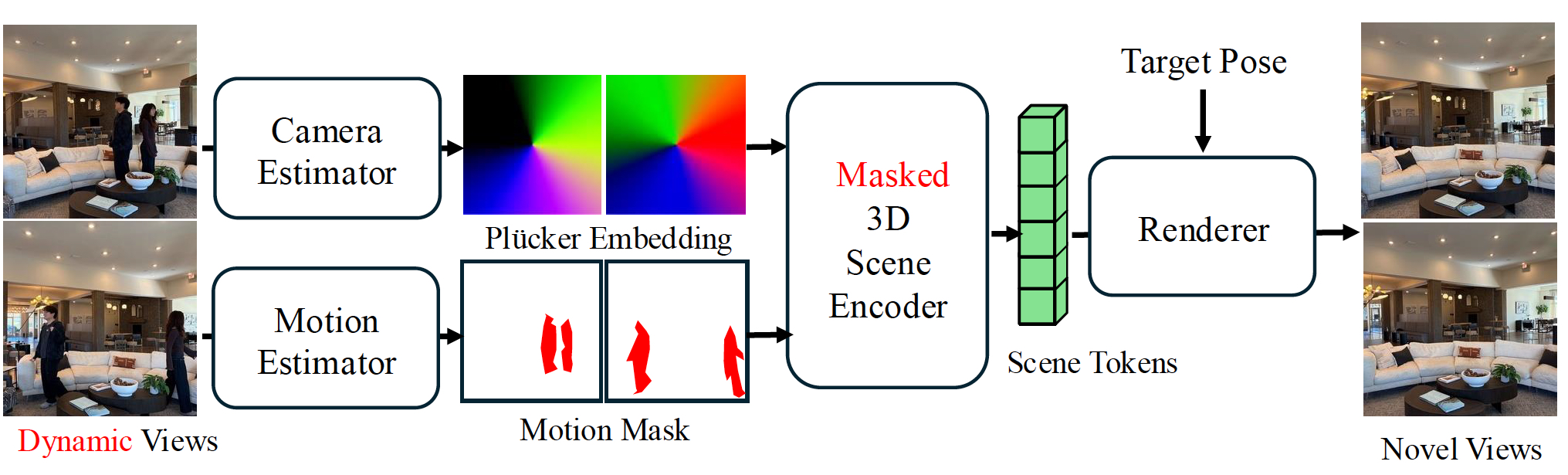
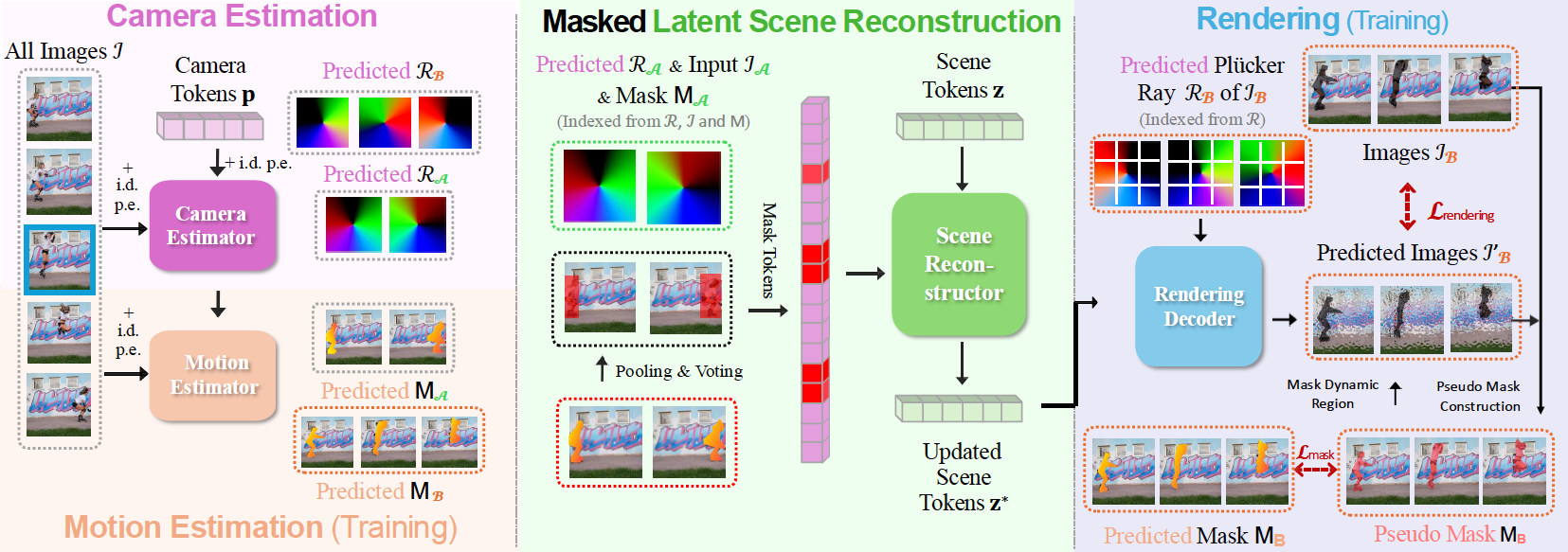
We target novel view synthesis from dynamic, in-the-wild videos where both the camera and scene undergo motion. Rather than relying on controlled captures, we mine diverse handheld footage from public sources.
Data Curation Pipeline: Our pipeline proceeds in three stages: (1) Source identification — querying YouTube channels for real-estate walkthroughs and indoor pet-interaction videos; (2) Image-level filtering — assessing visual quality and removing videos with intrusive overlays; (3) Sequence extraction — detecting scene cuts and subdividing clips based on camera translation to ensure sufficient parallax.
Benchmark Construction: We build two evaluation splits: D-RE10K Motion Mask providing motion annotations for 99 Internet video sequences, and D-RE10K-iPhone, a 50-sequence real-world paired transient/clean dataset captured with tripod-mounted iPhone for sparse-view transient-aware NVS evaluation.
Sample sequences showcasing diverse indoor scenes with transient objects.